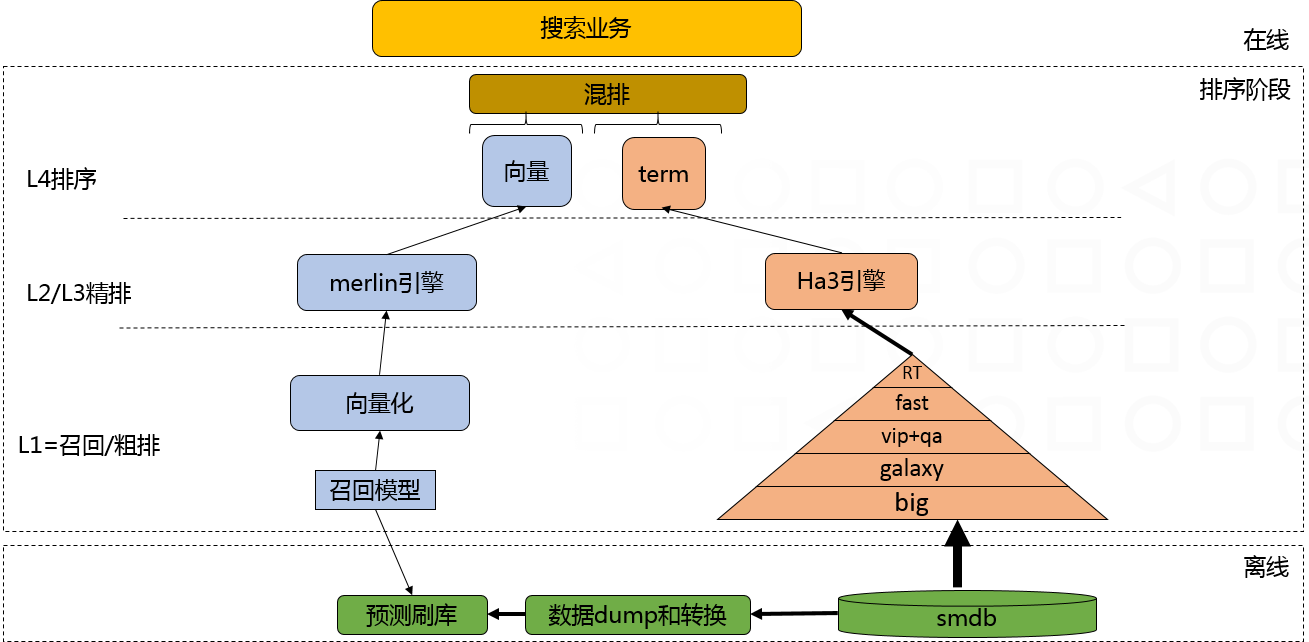
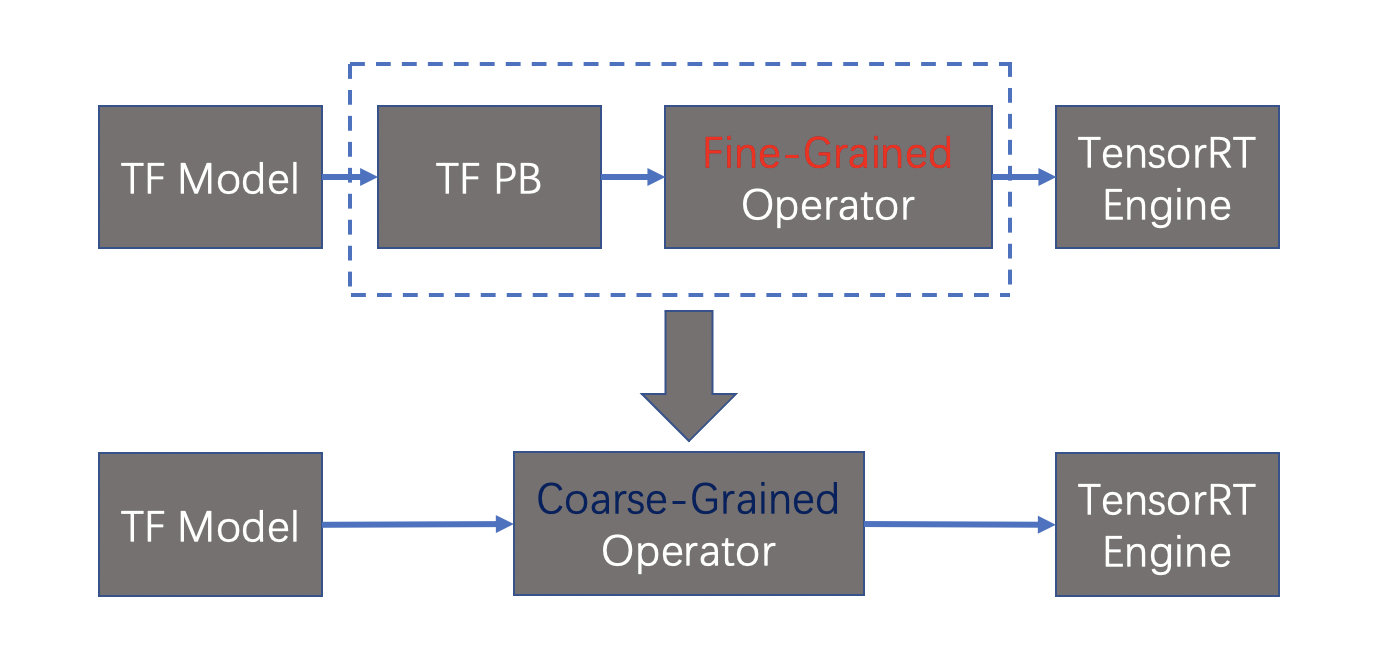
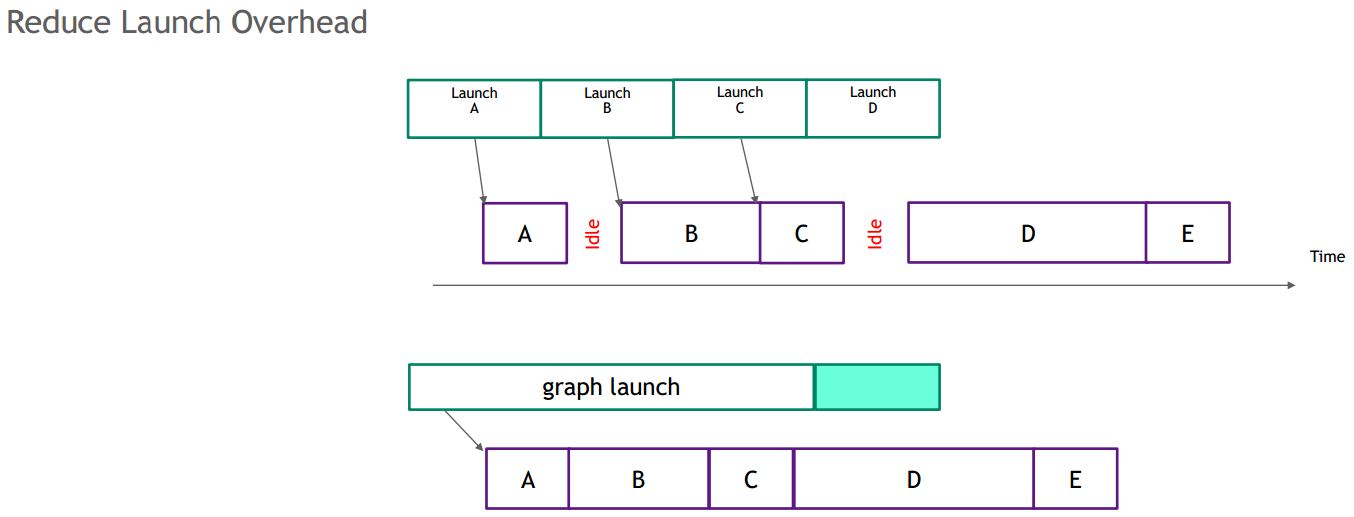
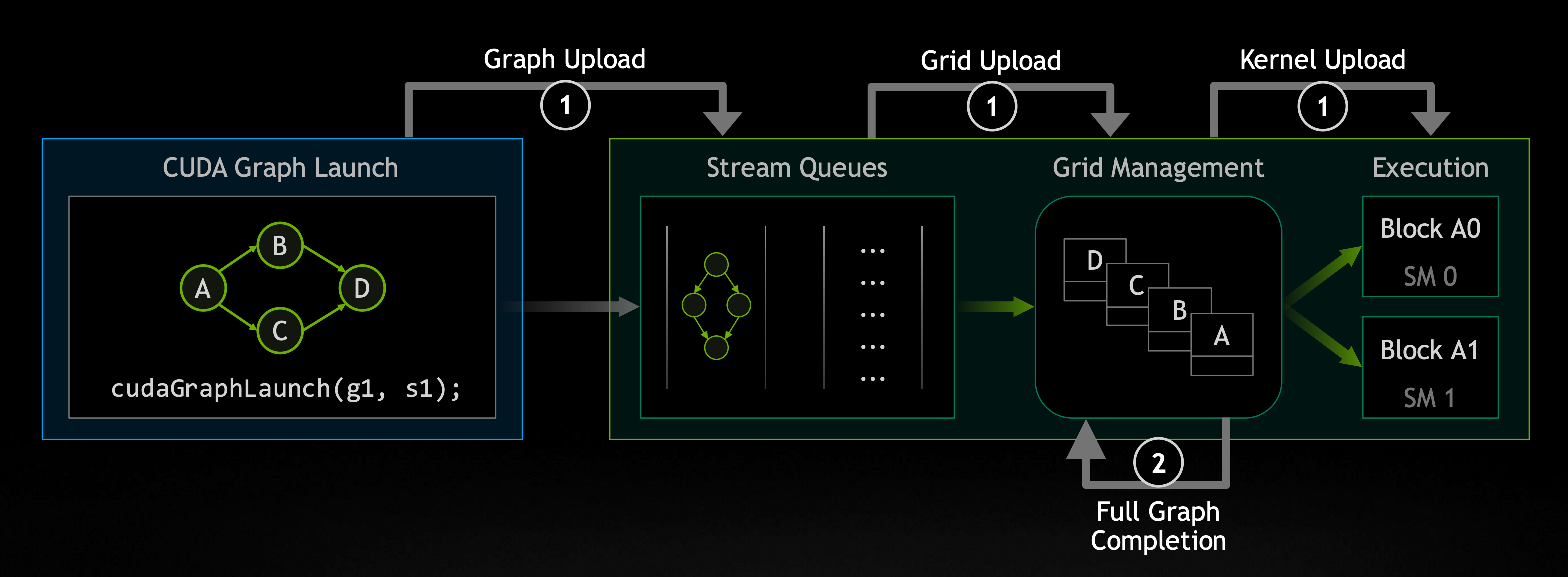
CUDA Graph是一个把所有kernel算子结合(capture)成Graph,然后整体launch这个Graph,减少频繁的kernel launch来带的开销以及kernel中间的gap。下图是普通的kernel执行和Graph执行的区别。可以看出,在kernel执行时因为需要CPU和GPU切换,造成小算子间会有比较大的GPU idle时间(gap引起),同时如果小算子执行的时间比较短,那么launch的时间占比就成了大头,造成GPU利用率低下。
从机制图可以看到,CUDA内部在执行Graph时,查找依赖关系,如果发现无直接依赖且目前资源满足算子执行(比如:stream processor/share memory/register等)则并行执行,提高GPU利用率。同时我们也对CUDA Graph下做了一些优化(比如增加memory cache机制、graph min update、multi-stream处理等)更好地提升了性能。
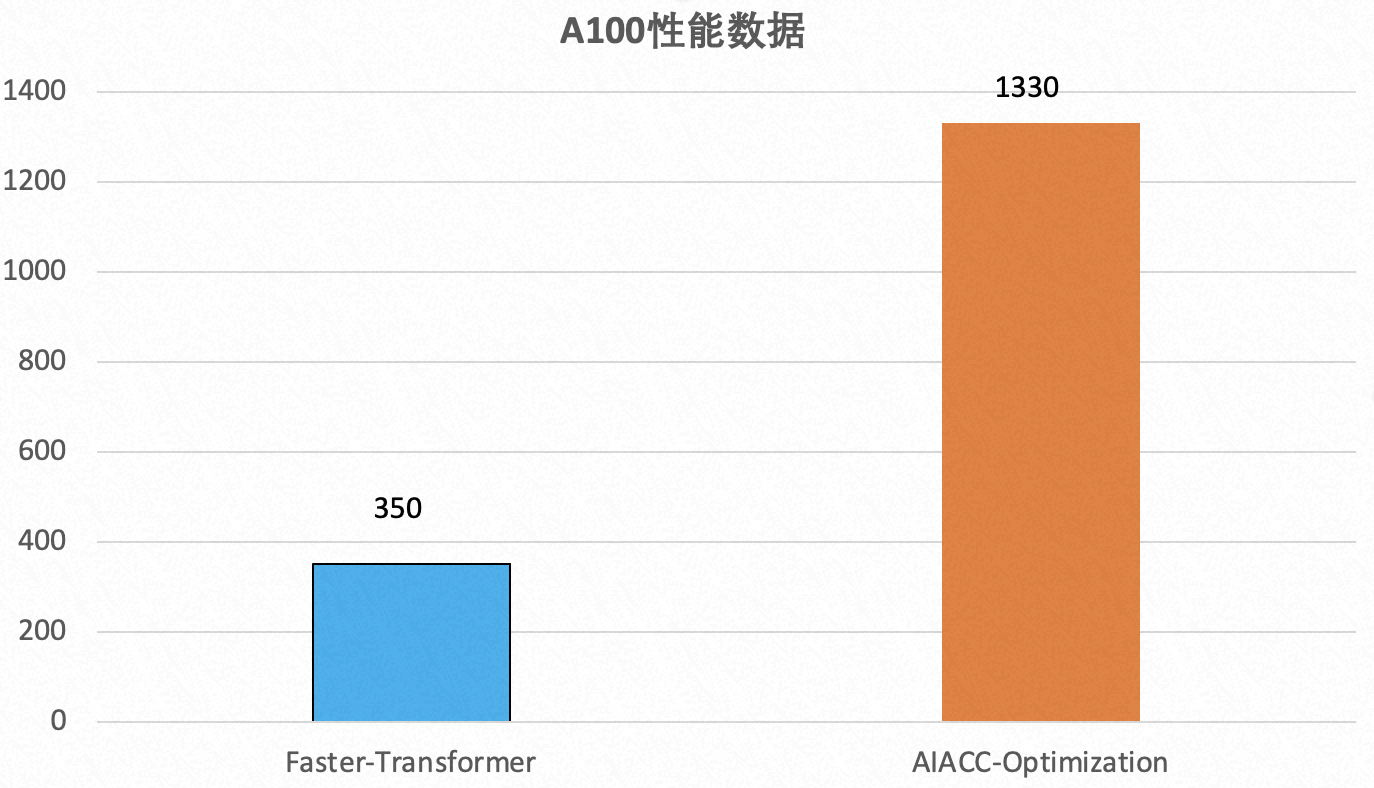
Enable CUDA Graph有两种方式,其中流捕获提供了一种从现有的基于流的 API 创建图的机制。在QTC模型中,通过流捕获的方式来加速基于TensorRT构建的图。Enable CUDA Graph后,在A100上延迟有3%下降,吞吐提高了4%,在GPU使用率高时latency也更稳定。
业 务 结 果


 发表于 2022-9-21 15:28:17
发表于 2022-9-21 15:28:17