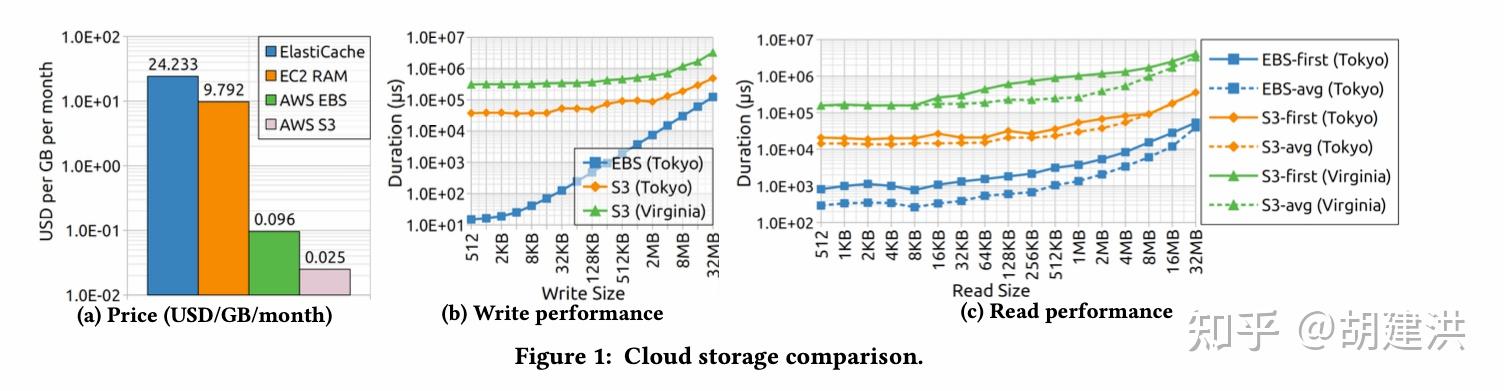
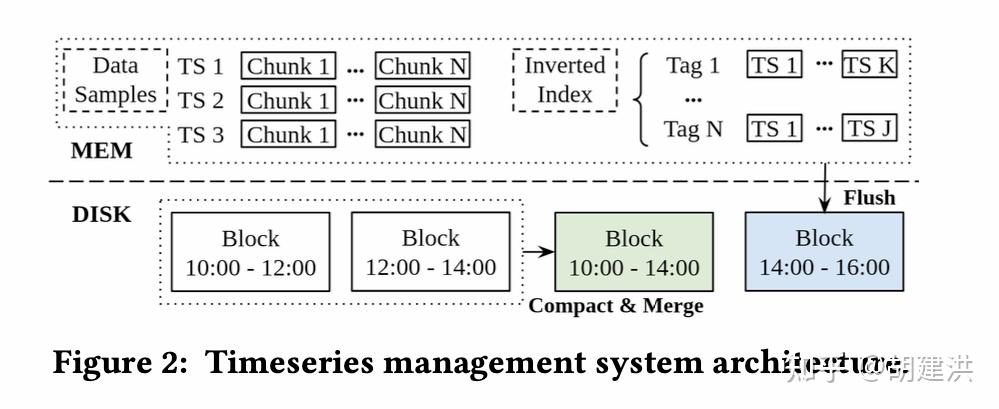
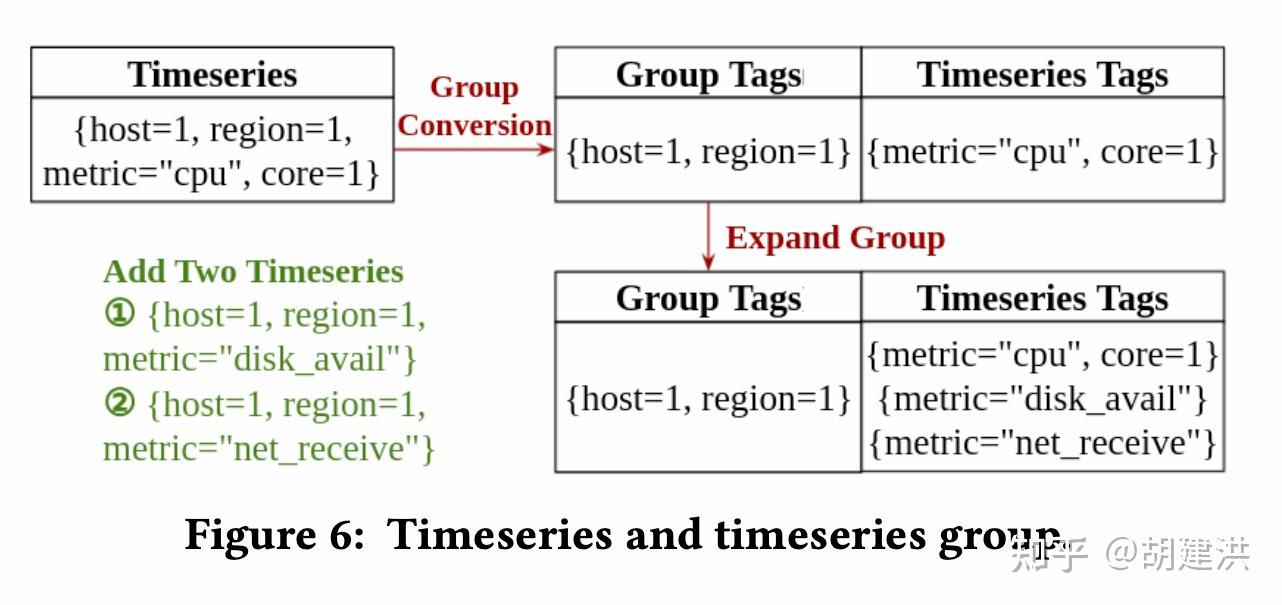
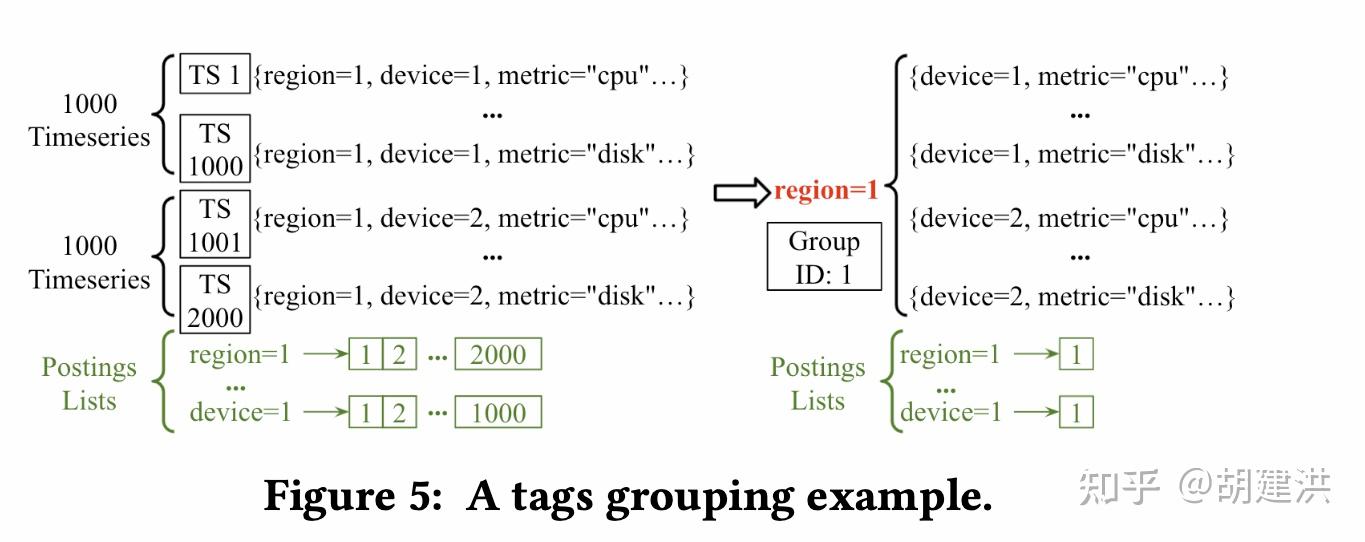
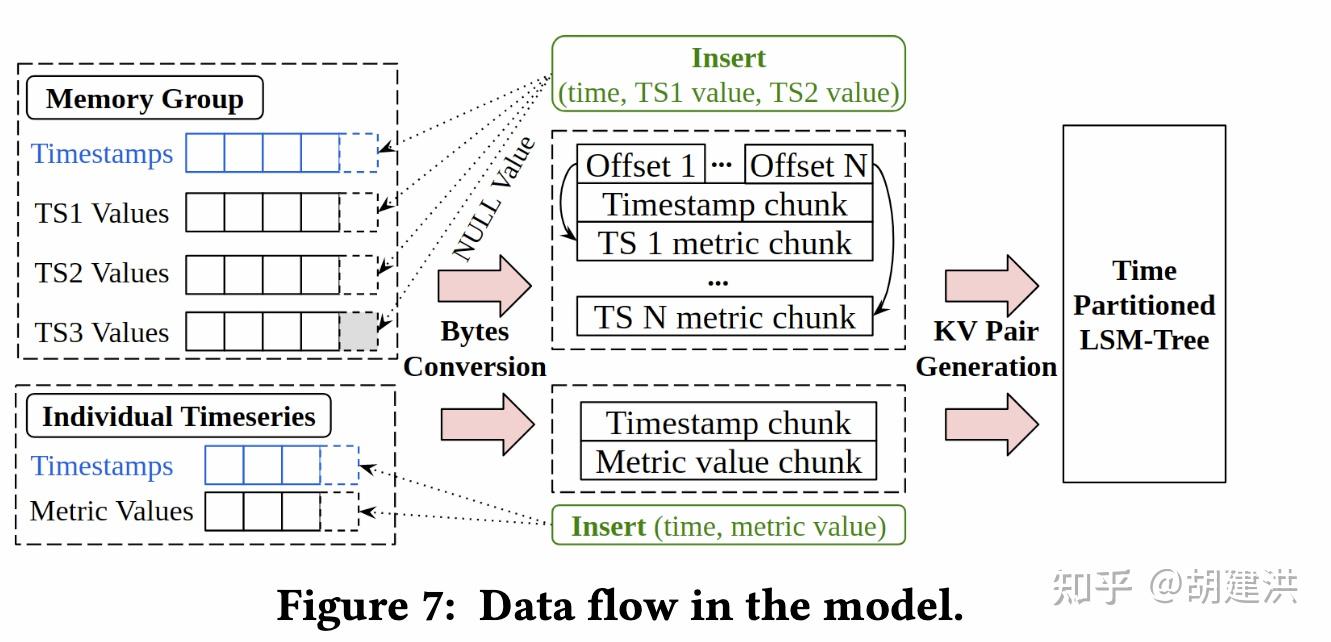
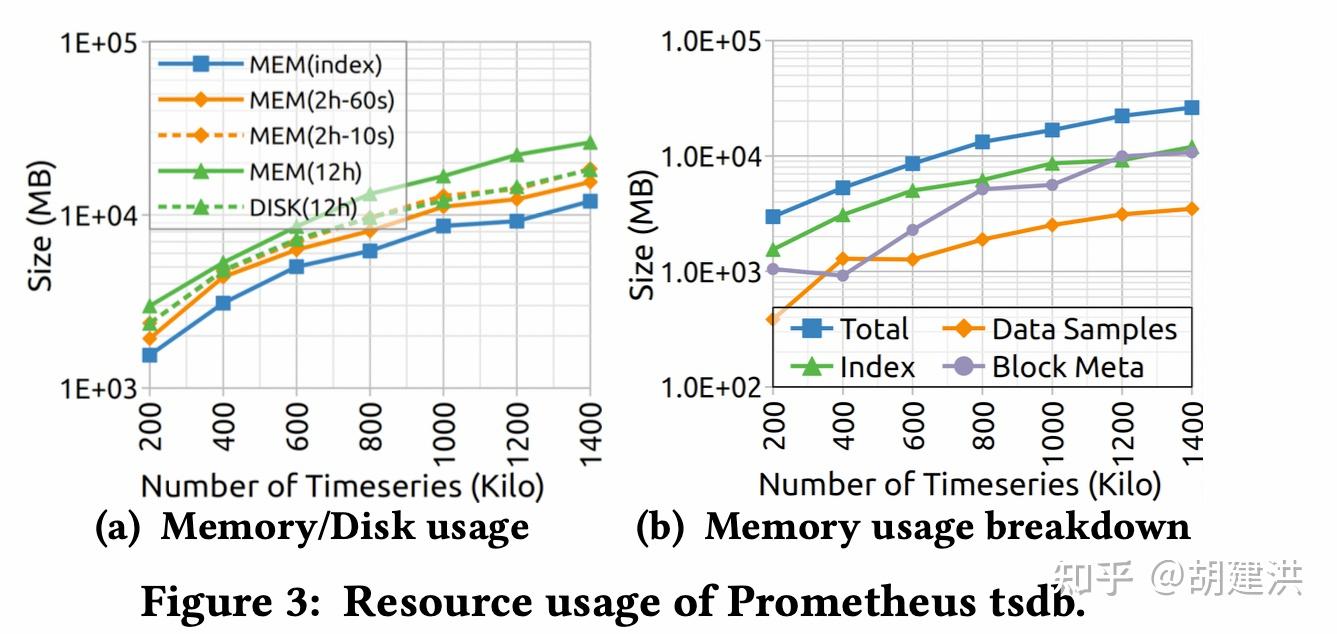
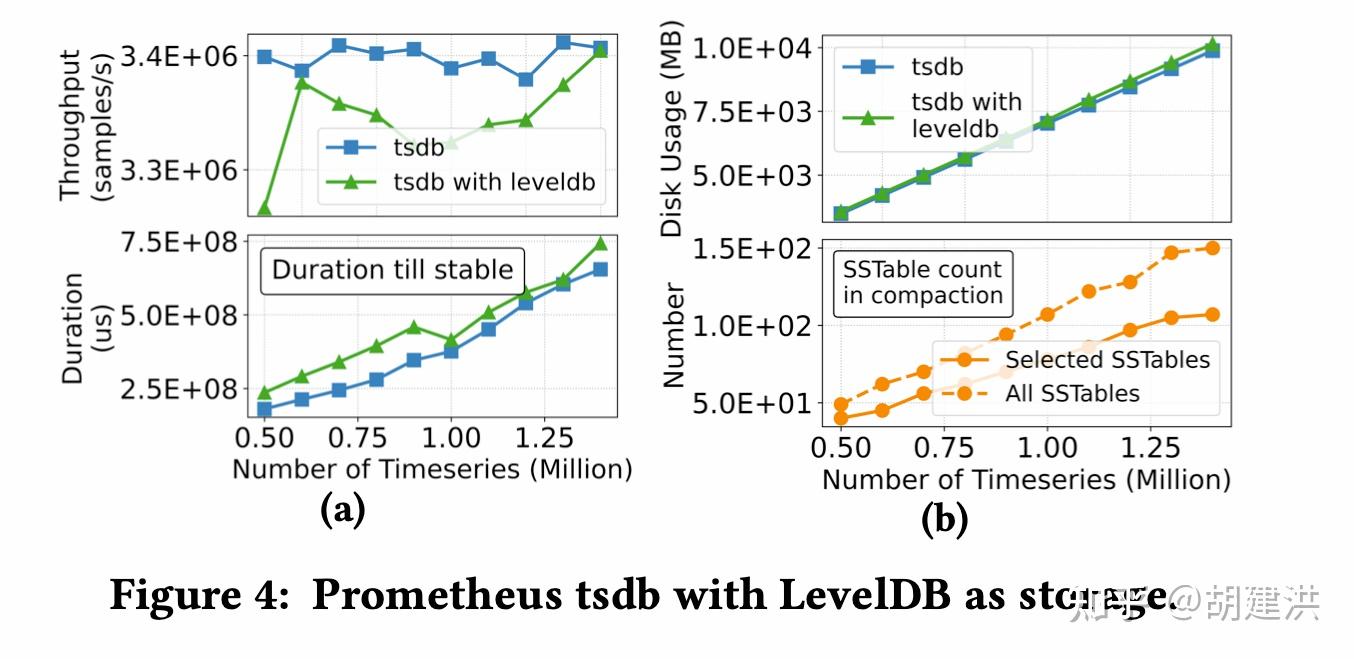
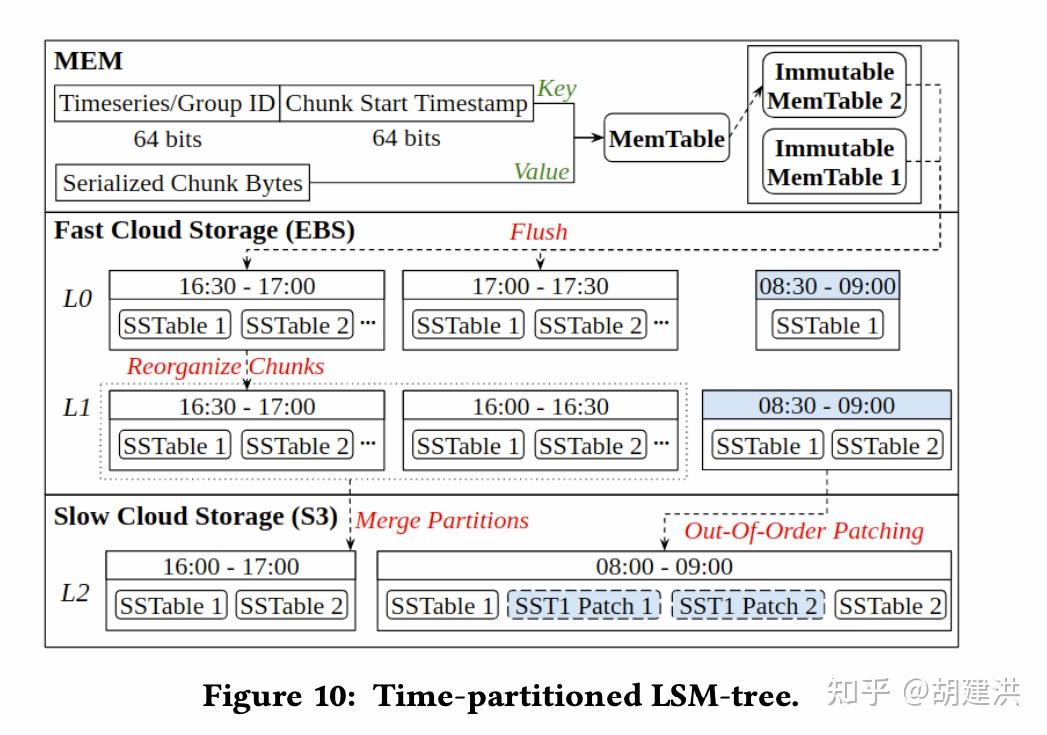
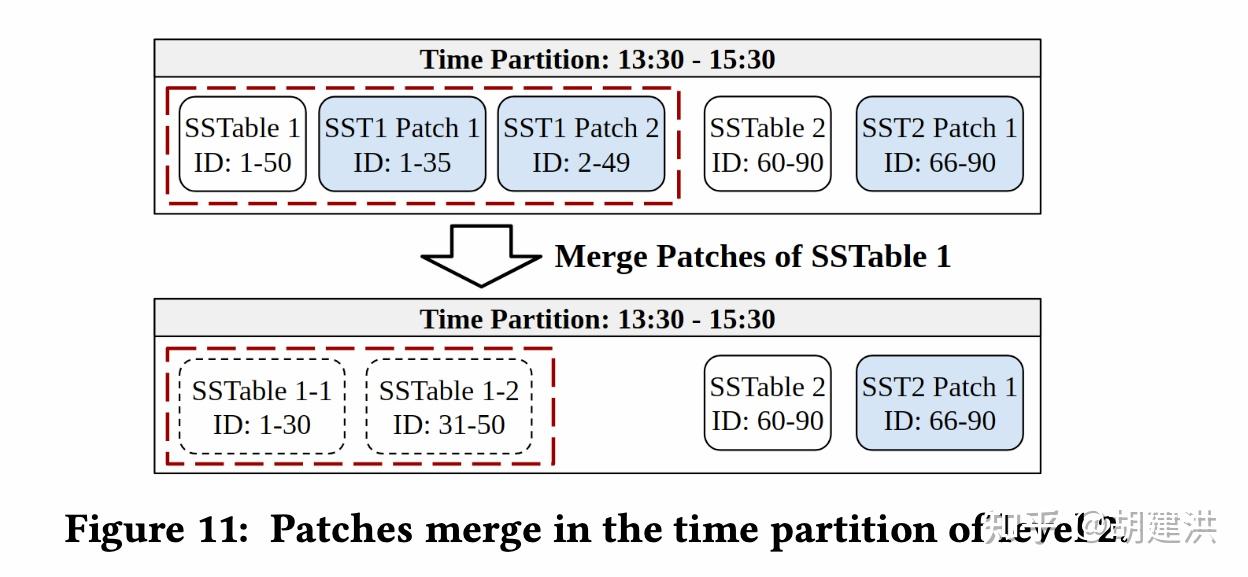
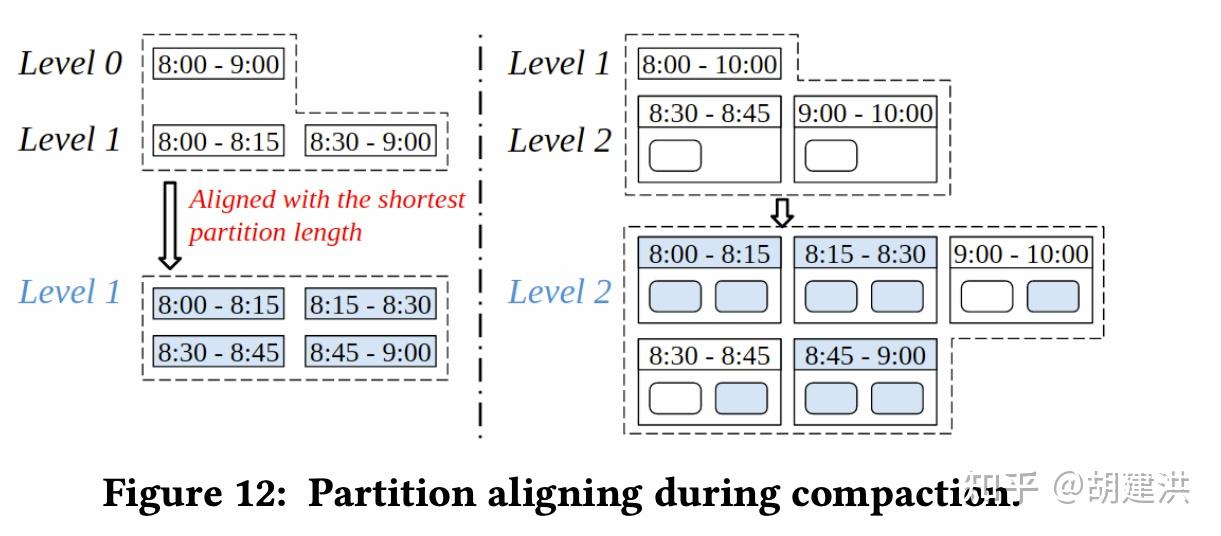
本文阅读了下SIGMOD'22发表的有关时序数据库的一篇论文,论文题目为:《TimeUnion: An Efficient Architecture with Unified Data Model for Timeseries Management Systems on Hybrid Cloud Storage 》,即一种具有统一数据模型和混合云存储支持的高效时间序列管理系统架构。论文先阐明了当前时序数据存储管理上存在的问题和面临的挑战,然后针对这些挑战在数据模型、内存结构、弹性时间分区LSM-Tree等几个方面提出了相应的解决方案,并通过实验验证了这些方案是可行的。文中斜体为笔者注。
论文原文下载地址。论文代码下载地址。
背景


 发表于 2022-11-29 13:45:06
发表于 2022-11-29 13:45:06